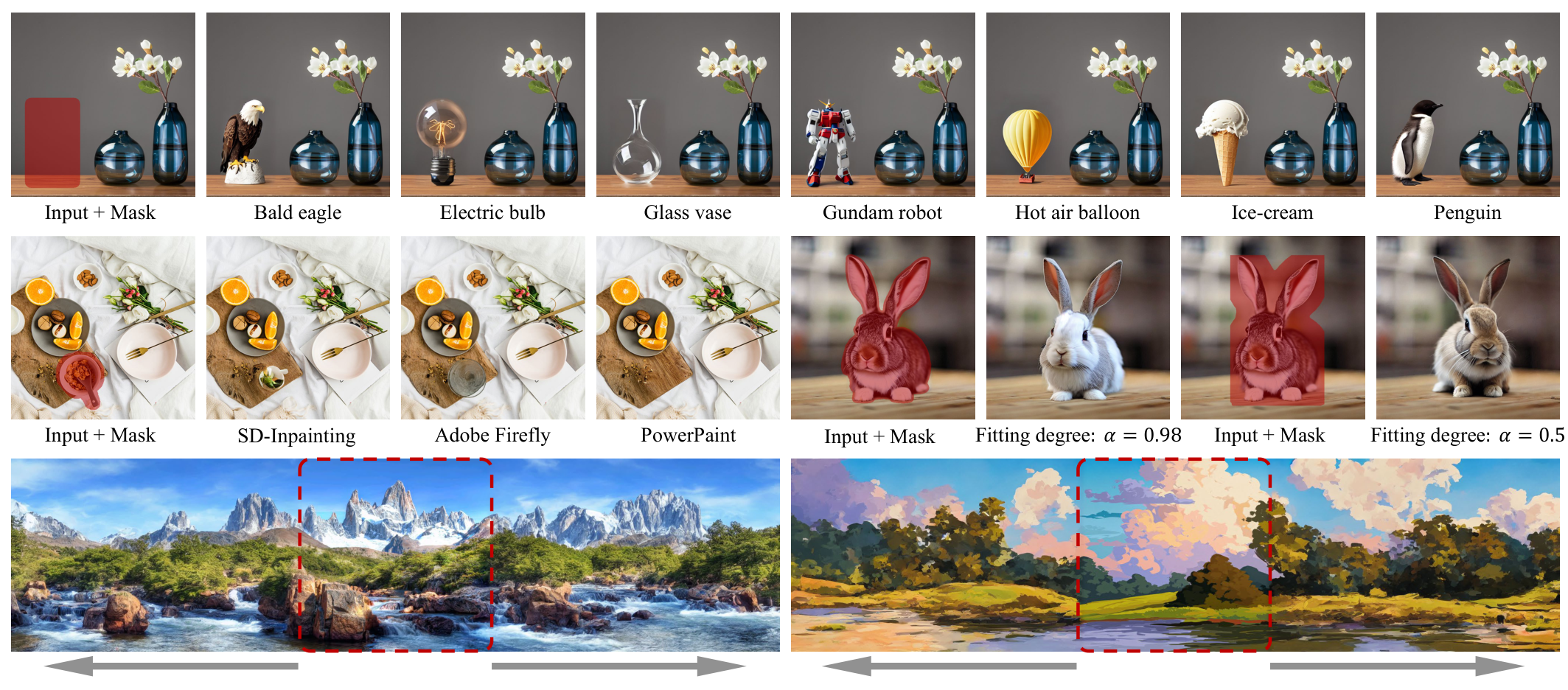
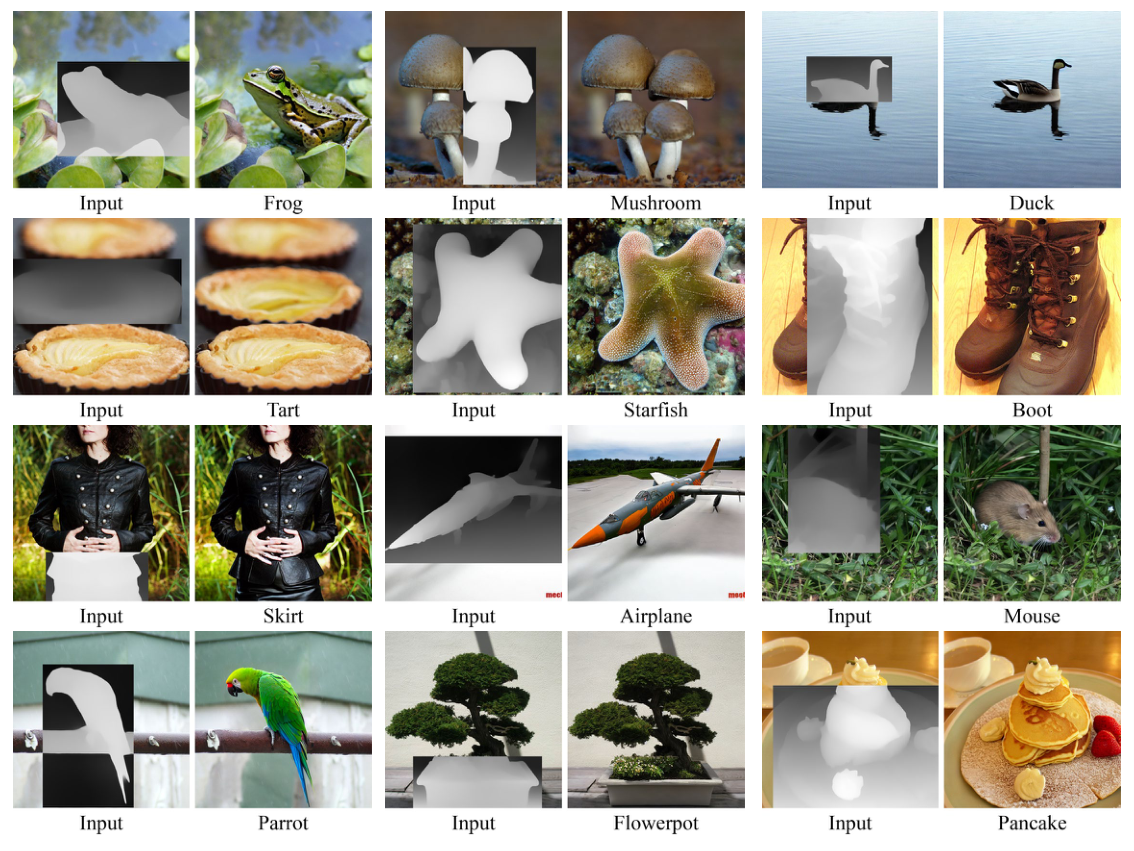
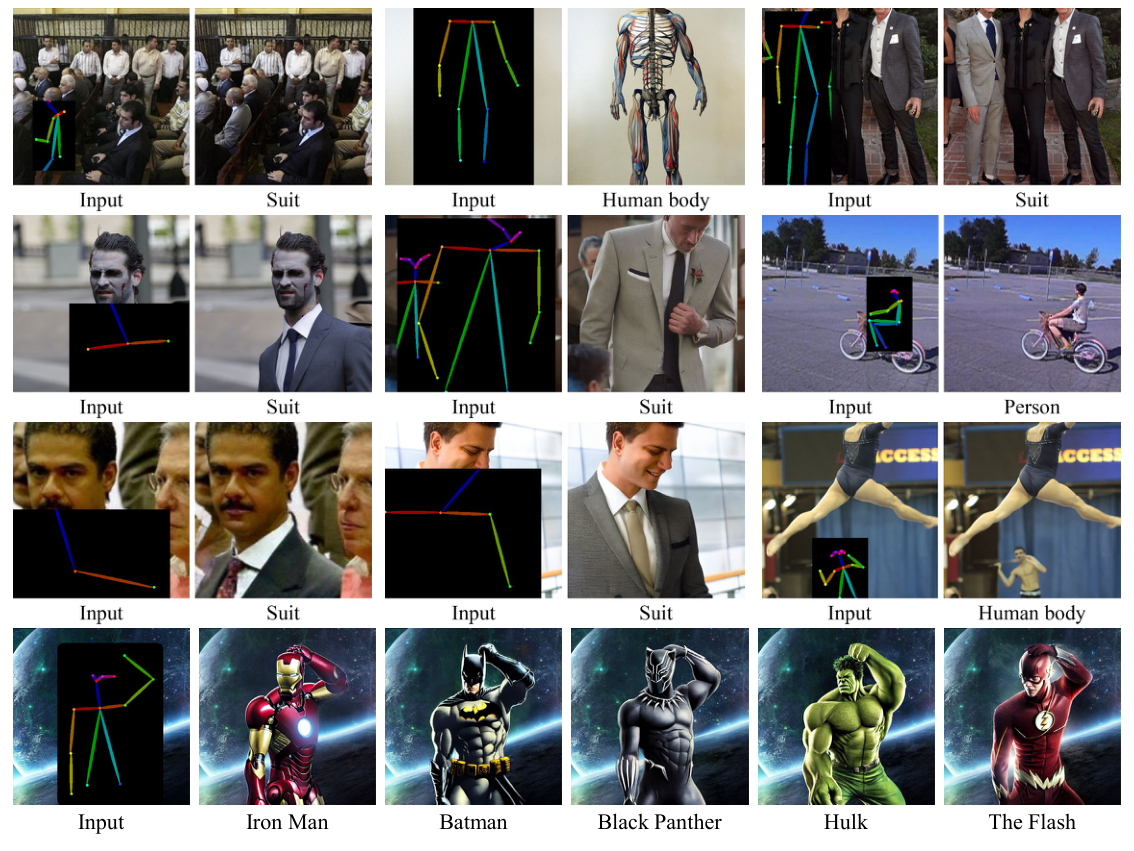
PowerPaint is the first versatile image inpainting model that simultaneously achieves state-of-the-art results in various inpainting tasks such as text-guided object inpainting, context-aware image inpainting, shape-guided object inpainting with controllable shape-fitting, and outpainting.
Abstract
Achieving high-quality versatile image inpainting, where user-specified regions are filled with plausible content according to user intent, presents a significant challenge.
Existing methods face difficulties in simultaneously addressing context-aware image inpainting and text-guided object inpainting due to the distinct optimal training strategies required.
To overcome this challenge, we introduce PowerPaint, the first high-quality and versatile inpainting model that excels in both tasks.
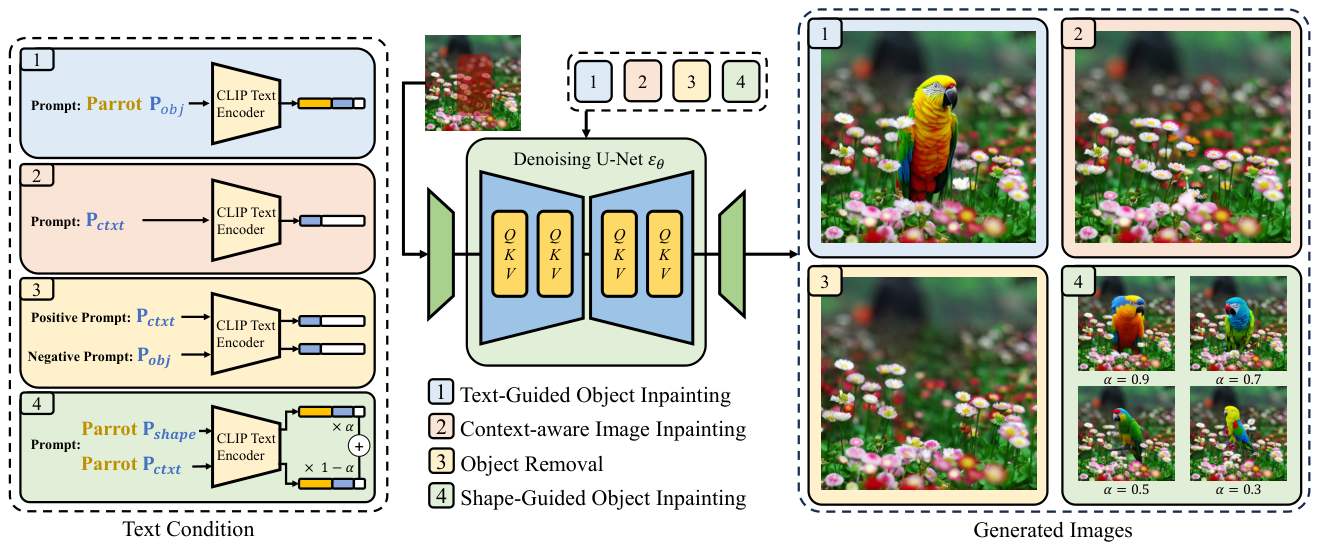
First, we introduce learnable task prompts along with tailored fine-tuning strategies to guide the model's focus on different inpainting targets explicitly. This enables PowerPaint to accomplish various inpainting tasks by utilizing different task prompts, resulting in state-of-the-art performance.
Second, we demonstrate the versatility of the task prompt in PowerPaint by showcasing its effectiveness as a negative prompt for object removal. Additionally, we leverage prompt interpolation techniques to enable controllable shape-guided object inpainting.
Finally, we extensively evaluate PowerPaint on various inpainting benchmarks to demonstrate its superior performance for versatile image inpainting. We will release the codes and models publicly, facilitating further research in the field.
Method
PowerPaint fine-tunes a text-to-image model with two task prompts, i.e., Pobj and Pctxt, for text-guided object inpainting and context-aware image inpainting, respectively. Specifically, Pobj can be used as a negative prompt with classifier-free guidance sampling for effective object removal. We further introduce Pshape for shape-guided object inpainting, which can be further extended by prompt interpolation with Pctxt to control how closely the generated objects should align with the mask shape.
@inproceedings{zhuang2024task,
title={A task is worth one word: Learning with task prompts for high-quality versatile image inpainting},
author={Zhuang, Junhao and Zeng, Yanhong and Liu, Wenran and Yuan, Chun and Chen, Kai},
booktitle={European Conference on Computer Vision},
pages={195--211},
year={2024},
organization={Springer}
}